|
Backup Data Properly
Computer data is very likely important to you, especially those of us who make a living in information technology. Technology has advanced at a rapid rate making our lives so much easier. This rapid advancement has created an explosion in data and the need for data protection. Loss of data could be a catastrophic loss for most businesses. Even though the computer has become a lot more reliable over the years computers have been known to fail. It is practically impossible to prevent computers from ever failing and losing data. The best way to ensure that you never lose your data is to back it up and keep backing it up. Backing up a single individual computer is relatively straight forward however in the enterprise environment things can be a lot more complicated. There is usually a variety of operating systems, server and workstation types and applications that need data protection. Most enterprises require a very low recovery time objective (RTO) for critical systems and applications making high availability systems and backups absolutely critical to the business. There are a number of open source backup products on the market such as Amanda, Backup PC, Bacula, Bareos, Box Backup, Burp and several more. The type of backup software you install will depend on several factors such as the type of system you need to protect, data type you need to protect, The allowable downtime and data loss that is acceptable if any (RTO and RPO), and there is cost to factor in is you want a commercial product that would come with updates and support. You should at a minimum back up your computer data at least once a week, with once per day being the recommended way to do it. In the past, the floppy disc was the main methods used to back up computer data lol wow have things changed good riddance floppy disk!! You were too slow, unreliable and cumbersome. You should back up your entire hard drive or create an image of it using software such as PING, Clonezilla, Runtime, Paragon and this are just a few of the free utilities out there. Backing up your entire hard drive is something that everyone should do, as it is indeed one of the best and most reliable ways to backup your computer. When you create a backup of your entire hard drive, it will copy all of your information, so if something happens you’ll always have your data. Doing a full backup of your hard drive is highly recommended even though it can be time consuming. Incremental backup should be performed daily at a minimum or more frequently if the data is critical like a production database. If what you have on your computer is very important, you’ll find it more than worth the effort and time needed to back things up. Another way you can back up your data, programs, and files, is to burn them directly to a data CD or DVD. This works fine for home users to archive data for long term retention. If you use CD/RW or DVD/RW disks, you can continue to add information to them when you create a backup. If you don’t use the RW (re-writable) media, then you won’t be able to go back and add more information to the disc. Burning data directly to discs are the method of backup that most people are using these days, although backing up the entire hard drive is the preferred way of backing up your data. If you plan to use discs, you’ll need either a CD or DVD burner, which you can get for a great price these days. The discs are cheap as well, which only makes this method of backing things up that much better. Whether it’s for your business or for personal reasons, you can’t go wrong backing up your data. You should always strive to back things up properly, as this will ensure that the data will always be there when you need it. This way, if your computer happens to crash or you lose everything on your hard drive, you’ll always have your backup files to go back to. This in itself can save you a lot of time, effort, and quite possibly even money - just for the simple fact that the files are all but a copy away to restore. Julius Williams
0 Comments
 The industry shift to the NVMe standard has started. More and more vendors are bringing products which are stamped NVMe.
NVM Express (or NVMe) stands for Non-Volatile Memory. NVMe has larger queue depth than SCSI (64000 over 254 for SAS, or 31 for SATA). NVMe Host Controller Interface Specification (NVMHCI), is a specification for accessing solid-state drives (SSDs) attached through the PCI Express (PCIe) bus. NVMe standard will allow up to six times faster data transfer speed than 6 Gbps SAS/SATA SSDs. NVMe Benefits and advantages While NVMe is new as technology, it’s just a question of a time when this standard will become a mainstream. Here is a quote from the release notes documents. I/O requests in an enterprise ecosystem spend much of their time in the hardware infrastructure (that includes NAND flash media, the flash controller, the host bus adapter, related hardware, etc.), and only a small portion of time working through the software I/O stack. The NVMe standard streamlines the software I/O stack by reducing unnecessary legacy overhead and supporting multiple queues, and many more commands per queue than any other commonly used storage protocol. NVMe supports 64,000 commands per queue (as well as 64,000 queues) to enable extremely fast hardware responses especially when compared to the SAS protocol that can only support 254 commands per queue or the SATA protocol that supports 31 commands per queue. NVMe Vs AHCI The AHCI (Advanced Host Controller Interface) command protocol was designed for much slower media (e.g., spinning magnetic disks). AHCI ends up being inefficient with modern SSDs, so a new standard was developed: NVMHCI (Non-Volatile Memory Host Controller Interface). Combine NVMHCI with a fast PCIe interface and you have NVMe, Non-Volatile Memory Express. It’s a much improved interface developed around the needs of flash memory rather than spinning disks. All applications are latency-sensitive to some extent, but some applications require the utmost performance - a few milliseconds of excess latency in the storage layer can result in seconds of delay at the application level. Enterprise SSDs weigh in to provide the best mix of cost, capacity and performance for the most latency-sensitive applications, but inconsistent performance is the hidden killer of application performance. Some of the Major Feature of PCIe SSDs are: Scalable performance; Better power management; Lower latency data transfers; Lower overhead; Advanced Error Reporting (AER); Maximized interconnect efficiency; Native hot plug capability; High-bandwidth, low pin count implementations; Hardware I/O virtualization; Software compatibility with existing PCI. PCI Express or Peripheral Component Interconnect Express (PCIe) is a relatively new, high-speed serial bus. It is a standards-based, bidirectional, point-to-point serial interconnect that's capable of data transfers of up to 32GB/s. The current PCIe standard is PCI 3.0. PCIe-based devices, like all other forms of SSDs, have no moving parts and can support consumer-based or enterprise-class NAND flash media. You can use PCIe SSDs as storage cache or as primary storage devices. Wired Extreme10 Gigabit Fiber and Wireless Extreme Gigabit wireless service coming to 87 US cities.12/24/2016 The World's Largest Telecoms Startup is bringing City-wide Wireless Extreme Gigabit service and 10 Gigabit Fiber to you! You haven't seen anything like this before. Angie is connecting thousands of buildings with 10 Gigabit fiber.
Wired Extreme and Wireless Extreme are two revolutionary developments. Angie is commoditizing Wireless Gigabit service and 10 Gigabit Fiber Optic connectivity. To find out when the roll-out for your city is scheduled Click Here 
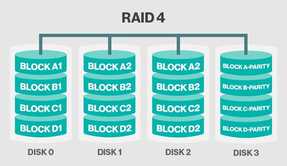 RAID 4 RAID 4
So you want to work as a Storage Engineer, With SANs and NAS, then you should have good working knowledge of some basic terms in storage and backup. I'm talking about RAID levels, which you must understand. RAID which stands for redundant array of independent disks is the most widely used data protection technology which is used today and multiple disks work as part of a set to provide protection against HDD failures. Striping, Mirroring & Parity are the three basics of RAID levels, which we are going to discuss. RAID Level 0 RAID 0 (Also known as a stripe set or striped volume) splits ("stripes") data evenly across two or more disks, without parity information, redundancy, or fault tolerance. Since RAID 0 provides no fault tolerance or redundancy, the failure of one drive will cause the entire array to fail; as a result of having data striped across all disks, the failure will result in total data loss. This configuration is typically implemented having speed as the intended goal. RAID 0 is normally used to increase performance, although it can also be used as a way to create a large logical volume out of two or more physical disks RAID Level 1 RAID 1 Consists of an exact copy (or mirror) of a set of data on two or more disks; a classic RAID 1 mirrored pair contains two disks. This configuration offers no parity, striping, or spanning of disk space across multiple disks, since the data is mirrored on all disks belonging to the array, and the array can only be as big as the smallest member disk. This layout is useful when read performance or reliability is more important than write performance or the resulting data storage capacity. The array will continue to operate so long as at least one member drive is operational Any read request can be serviced and handled by any drive in the array; thus, depending on the nature of I/O load, random read performance of a RAID 1 array may equal up to the sum of each member's performance, while the write performance remains at the level of a single disk. However, if disks with different speeds are used in a RAID 1 array, overall write performance is equal to the speed of the slowest disk. RAID Level 2 RAID 2, Which is rarely used in practice, stripes data at the bit (rather than block) level, and uses a Hamming code for error correction RAID Level 3 RAID 3, Which is rarely used in practice, consists of byte-level striping with a dedicated parity disk. One of the characteristics of RAID 3 is that it generally cannot service multiple requests simultaneously, which happens because any single block of data will, by definition, be spread across all members of the set and will reside in the same location RAID Level 4 RAID 4, Improves performance by striping data across many disks in blocks, and provides fault tolerance through a dedicated parity disk RAID Level 5 One of the most popular RAID levels, RAID 5 stripes both data and parity information across three or more drives. It is similar to RAID 4 except that it exchanges the dedicated parity drive for a distributed parity algorithm, writing data and parity blocks across all the drives in the array. This removes the "bottleneck" that the dedicated parity drive represents, improving write performance slightly and allowing somewhat better parallelism in a multiple-transaction environment, though the overhead necessary in dealing with the parity continues to bog down writes. Fault tolerance is maintained by ensuring that the parity information for any given block of data is placed on a drive separate from those used to store the data itself. The performance of a RAID 5 array can be "adjusted" by trying different stripe sizes until one is found that is well-matched to the application being used.   by TableauBy Jonah Kim | Friday, December 16, 2016 - 16:38
Source Article http://www.networksasia.net/article/2017-big-data-trends-tableau.1481877538 2016 was a landmark year for big data with more organisations storing, processing, and extracting value from data of all forms and sizes. In fact, a few months ago, IDC revealed that 53% of Asia Pacific (excluding Japan) organisations consider big data and analytics crucial for their business. The same findings also shared that enterprises in the region are in the early stages of big data analytics adoption and the growing volume of data, as well as mobility and the Internet of Things (IoT), will continue this shift. In 2017, systems that support large volumes of data will continue to rise. The market will demand platforms that help data custodians govern and secure big data, while empowering end users to analyse that data more easily than ever before. These systems will mature to operate well inside of enterprise IT systems and standards. Furthermore, the focus on big data analytics skills will continue to grow as it becomes a more central focus for enterprises across industries. Each year at Tableau, we start a conversation about what’s happening in the industry. In Singapore, specifically, the Economic Development Board (EDB) has predicted that the data analytics sector will likely add $1 billion in value to the economy by 2017. The discussion drives our list of the top big data trends for the following year These are our predictions for 2017. 1. A smarter everything, with big data skills In 2016, the Singapore government spoke about the growth of big data analytics in the nation and the demand for employees with such skills. As countries, cities, and communities continue to get smarter, the need for skilled talent in the big data analytics space will only continue to grow. Employees and governments will continue to focus on this – preparing the current and future workforce for jobs in this field. In Singapore itself, we have already seen the government launch several incentives to encourage the workforce to develop these skills, while more academic institutions offer relevant courses to their students. This will continue to take main stage in 2017. 2. Variety drives big-data investments Gartner defines big data as the three Vs: high-volume, high-velocity, and high-variety information assets. While all three Vs are growing, variety is becoming the single biggest driver of big-data investments, as seen in the results of a recent survey by New Vantage Partners. This trend will continue to grow as firms seek to integrate more sources and focus on the “long tail” of big data. Data formats are multiplying and connectors are becoming crucial. In 2017, analytics platforms will be evaluated based on their ability to provide live direct connectivity to these disparate sources. 3. The convergence of IoT, cloud, and big data create new opportunities It seems that everything in 2017 will have a sensor that sends information back to the mothership. In smart cities and nations, like Singapore, analysts have commented that products from the IoT sector will continue to feature. A year ago, Frost and Sullivan also projected that the number of connected devices will increase to 50 billion units globally in five years; this is equivalent to each person having ten connected devices. Across the region, IoT is generating massive volumes of structured and unstructured data, and an increasing share of this data is being deployed on cloud services. The data is often heterogeneous and lives across multiple relational and non-relational systems, from Hadoop clusters to NoSQL databases. While innovations in storage and managed services have sped up the capture process, accessing and understanding the data itself still pose a significant last- mile challenge. As a result, demand is growing for analytical tools that seamlessly connect to and combine a wide variety of cloud-hosted data sources. Such tools enable businesses to explore and visualise any type of data stored anywhere, helping them discover hidden opportunity in their IoT investment. 4. Self-service data prep becomes mainstream Making Hadoop data accessible to business users is one of the biggest challenges of our time. The rise of self-service analytics platforms has improved this journey. At the beginning of 2016, IDC predicted that spending on self-service visual discovery and data preparation will grow more than twice as fast as traditional IT-controlled tools for similar functionality (through till 2020). Now, business users want to further reduce the time and complexity of preparing data for analysis, which is especially important when dealing with a variety of data types and formats. Agile self-service data-prep tools not only allow Hadoop data to be prepped at the source but also make the data available as snapshots for faster and easier exploration. 5. Big data grows up: Hadoop adds to enterprise standards We're seeing a growing trend of Hadoop becoming a core part of the enterprise IT landscape. And in 2017, we’ll see more investments in the security and governance components surrounding enterprise systems. Apache Sentry provides a system for enforcing fine-grained, role-based authorisation to data and metadata stored on a Hadoop cluster. Apache Atlas, created as part of the data governance initiative, empowers organisations to apply consistent data classification across the data ecosystem. Apache Ranger provides centralised security administration for Hadoop. These capabilities are moving to the forefront of emerging big-data technologies, thereby eliminating yet another barrier to enterprise adoption. 6. Rise of metadata catalogs finds analysis-worthy big data For a long time, companies threw away data because they had too much to process. With Hadoop, they can process lots of data, but the data isn’t generally organised in a way that can be found. Metadata catalogs can help users discover and understand relevant data worth analysing using self-service tools. This gap in customer need is being filled by companies like Alation and Waterline which use machine learning to automate the work of finding data in Hadoop. They catalog files using tags, uncover relationships between data assets, and even provide query suggestions via searchable UIs. This helps both data consumers and data stewards reduce the time it takes to trust, find, and accurately query the data. In 2017, we'll see more awareness and demand for self-service discovery, which will grow as a natural extension of self-service analytics. Jonah Kim is the Product Manager for APAC at Tableau
Reduxio HX550: Simple, Efficient, Hybrid Flash Storage according to ESG Labs. "ESG Lab validated the Reduxio HX550 hybrid flash array with a focus on ease of use and performance. The HX550’s innovative architecture can bring the performance advantages of flash to more of your workloads; in addition, the Backdating feature serves as an enterprise-class “time machine,” enabling instant restore to one-second recovery points without using snapshots." Reduxio’s storage systems can be managed by CLI or using the web-based Reduxio Storage Manager from any desktop, laptop, or mobile device, and the interface is touch-ready. Each HX550 has dual controllers for high availability; redundant power supplies with battery backup; eight 800GB SSD drives and 16 2TB SATA drives; four 10GbE SFP+ iSCSI ports for data; and two 1GbE copper ports for system management. NoDup. Reduxio calls this feature NoDup because no duplicate data is stored on any media in the system. As data enters the array, it is chunked into 8K blocks and deduplicated, and the unique blocks are compressed—all in real time. Data after deduplication and compression is stored in the system’s DRAM cache. NoDup is global and always active, so no duplicate data is ever stored across SSDs or HDDs, or across volumes, clones, or historical data saved for data recovery. This makes the system extremely efficient. Tier-X. This automated, blocklevel tiering across SSD and HDD is always on. Deduplicated and compressed data is stored first on SSD, and as that fills, Tier-X algorithms identify the less-used data, which is then automatically moved to HDD with no administrative intervention. 
Compressing Files
When you want to upload a file or email a collection of files to a friend, it’s best to archive it as a .zip or .sit file first. This will decrease the time it takes for your computer to send it elsewhere, and it will also decrease the time it takes for someone else to download it. Lossless compression basically works by removing redundancy. What does that mean? Let’s simplify things. Say you have a file that is comprised of the following data: FFFFFIILLLEEEEEE We can represent the data as F5I2L3E6 Information that’s redundant is replaced with instructions telling the computer how much identical data repeats. This is only one method of lossless compression, of course, but it points to how this is possible. Other math tricks are used, but the main thing to remember about lossless compression is that while space is temporarily saved, it is possible to reconstruct the original file entirely from the compressed one. lossless compression the decompress stage returns the data back to the original contents. Lossless compression is used in databases, emails, spreadsheets, office documents and source code to name a few. Lossy compression does not return the data back to the original contents. Lossy compression is used with music, photos, videos, medical images, scanned documents, and fax machines. To create your own .zip or .sit file, you can select a single file or a group of files from within Explorer, and right-click the selection. Again, depending on how you installed Winzip or StuffIt, you can click the “Add to Zip” or “Add to Sit” option and have these programs automatically archive the file(s) into one. Decompressing Files Assuming that you have Winzip or StuffIt installed on your computer, you can access the files archived inside a .zip or .sit file by simply double-clicking the archive (a file ending in a .zip or .sit extension). Double-clicking one of these kinds of files will open up a window that displays the contents of the archive. In most cases, you can double click a file inside this window to use it, or you can select it and drag the file to a folder to view later. Depending on how you elected to install Winzip or StuffIt, you may be able to right-click a .zip or .sit file and have the program extract its contents into a new folder for you. Some files compress better than others and in some instances, you may not notice that much of a difference. The files that compress the best are images, documents, and multimedia files. Executable files (files that end in an .exe extension) don’t compress that well, however when they’re archived with a sizable number of other files, they compress rather well. Click Here! Julius Williams Garland, TX Mckinney, TX Dallas, TX  In computer terminology, a ‘server’ is a device that supports and provides functionality for other devices and programs, typically called ‘clients’. This is what is referred to as the ‘client-server model’ in network computing where a single overall computation distributes data, functions and processes across multiple devices and computer processors. Among the many services that servers provide are sharing of resources and data between clients and performing multiple computing tasks. A single client can use multiple retainers and conversely a single retainer can also serve multiple clients.
Client-Servers today function on the ‘request-response’ model where a client needs a task done and sends a request to the retainer which is accomplished by the server. A computer designated as ‘server-class hardware’ means that is a specialized device for running server functions. Though the implication leads to visions of large, powerful and reliable computer devices, in reality, a retainer may be a cluster of relatively simple components. Servers play a very significant role in networking; any retainer that takes a hit in functioning can bring to a halt the connectivity of all the computers in a network. The significant rise of Internet usage around the world has boosted the development of servers for specific functions. This is an element that is constantly undergoing changes and we will have to wait and see how servers will be developed for future computational needs. Servers are categorized according to their tasks and applications. Dedicated retainers perform no other networking tasks other than retainer tasks assigned to them. A server platform is the underlying system hardware or software that drivers the server; it is much like an operating system in a desktop, laptop or other devices. Types of servers – A Server platform is the fundamental hardware or software for a system which acts as an engine that drives the server. It is often used synonymously with an operating system.
Click Here! Julius’ PR Site Please visit my other blog sites Julius Williams All About Data Storage Julius' Blog This article is from the register located at http://www.theregister.co.uk/2015/07/09/symantec_said_to_be_selling_veritas_to_private_equity_firm/ Symantec’s soon-to-be-split-off Veritas business is destined for private equity ownership, according to Bloomberg. The buyer is said to be the Carlyle Group and it will pay something between $7bn and $8bn for a business, which has forecast $2.6bn annual revenues. It’s been noted for some time that there is no CEO identified for Veritas, whereas the Symantec side of the business has Michael Brown in place. HP – which is similarly separating itself into two businesses – has its two CEOs identified. Often, a PE buyer of a business will install their own CEO, as is he case with Jonathan Huberman running the Syncplicity business for Skyview Capital. Symantec bought Veritas for $13.5bn in 2005, so it’s making a rather large loss on the deal, if it takes place. A sale to PE would raise guaranteed cash, whereas turning Veritas into a publicly treaded business would give it shares, which it would have to sell at a price set by the market over a longish period, so as not to depress the share price. Veritas has four lines of business:
|
Blog AuthorJulius W. ArchivesCategories |
Data Storage and Backup & Recovery
 RSS Feed
RSS Feed
